
What is Cortex AI? Cortex AI is Snowflake’s native AI solution…
Data Flow: What Is It?
 Data in motion, or streaming data, involves tools around capturing, routing and processing data. It also naturally leads into discussions around the best place to store or land the data for end user and system use. Different tools connect better to different sources, so defining what type of data we’re capturing is important. Are we looking to capture external data? Internal data on site? Internal data on the cloud? A mix of both? And beyond the overall location of the data to be captured, what is the mechanism? Will this data be “pushed” to the system, or need to be “pulled” from another system? After data is captured comes the meat of streaming data analytics: processing. What needs to be done with/to the data right after it’s captured? We’ll touch on more in depth on this critical step in the next section. And last but not least, storage. How are end users or systems needing to interact with this data in motion, or once it’s landed. Many streaming data challenges are around this question and solution.
Data in motion, or streaming data, involves tools around capturing, routing and processing data. It also naturally leads into discussions around the best place to store or land the data for end user and system use. Different tools connect better to different sources, so defining what type of data we’re capturing is important. Are we looking to capture external data? Internal data on site? Internal data on the cloud? A mix of both? And beyond the overall location of the data to be captured, what is the mechanism? Will this data be “pushed” to the system, or need to be “pulled” from another system? After data is captured comes the meat of streaming data analytics: processing. What needs to be done with/to the data right after it’s captured? We’ll touch on more in depth on this critical step in the next section. And last but not least, storage. How are end users or systems needing to interact with this data in motion, or once it’s landed. Many streaming data challenges are around this question and solution.
Types of Data Processing
Batch processing is when newly arriving data elements are collected into a group and the entire group is processed at a future time. This is often based on a set metric, such as time, size, or trigger based. As we decrease these processing intervals, the term microbatch may come into play. In microbatch, intervals are getting quite small, and time to use is getting quicker, but data is still processed a batch at a time. With streaming data processing, each newly arriving data element is processed when it arrives, as an individual piece at a time. We can also have stateful and windowing streaming processes that allow reference to historical and intervals of data, but the process is triggered on an element-by-element basis as data is received.
Streaming Challenges
Velocity and Variety
The first challenges of streaming data are a throwback to a couple of the well-worn 3-V’s of Big Data: velocity and variety. How many events are coming into the streaming system, and how long does the data need to be accessible in the streaming analytics side of the house? Also, how soon does the data (raw or enhanced) need to be available to end users and systems? The performance and scalability of a chosen streaming data tool needs to fit with the expected streaming data velocity requirements. When speaking of variety as a challenge of streaming data, we’re moving beyond the logs that many streaming solutions started with, and into questions such as: What is the footprint of the events that are being streamed? What validation and governance needs to be applied to the variety of events accepted into the streaming tool? Will this data footprint evolve as maturity increases and streaming data analytics is implemented?
Access
Another challenge of streaming data, along with many other data solutions, is access. After the capturing and processing of the streaming the data is done, how does the business plan to use these near-real-time insights? Does the streaming data need to be landed into a storage system for real-time queries of individual elements, dashboarding, or traditional reporting purposes? This could include data structures and corresponding access controls such as relational databases, NoSQL, object stores such as S3, or full text search indexes such as Elasticsearch. In addition to access through appropriate storage solutions, does the prepared streaming data need to be fed into a downstream analytics model for real-time scoring, ranking or anomaly detections? In what form will end users be most comfortable interacting with this streaming data in? Does the access of choice include languages such as python, java, or more drag and drop self serve analytics through cloud solutions?
Maintenance
A final challenge of streaming data to mention is maintenance. Stream processing is about a continuous and unbounded flow of data, which requires a different maintenance mentality than batch processing which we may be more used to. When it comes to mediation, questions arise such as: How will we handle message duplicates? When not working in a batch, it is much more difficult to go back and rewrite or compare incorrect states. How will we handle backwards compatibility of streaming data with existing systems? Strategies to implement and maintain desired streaming data quality involve exercises such as establishing time to live (data expiration) policies on streaming data feeds, and orchestration of the processing of the data by splitting complex requirements into smaller microservices.
Data Flow: What’s Its Value?
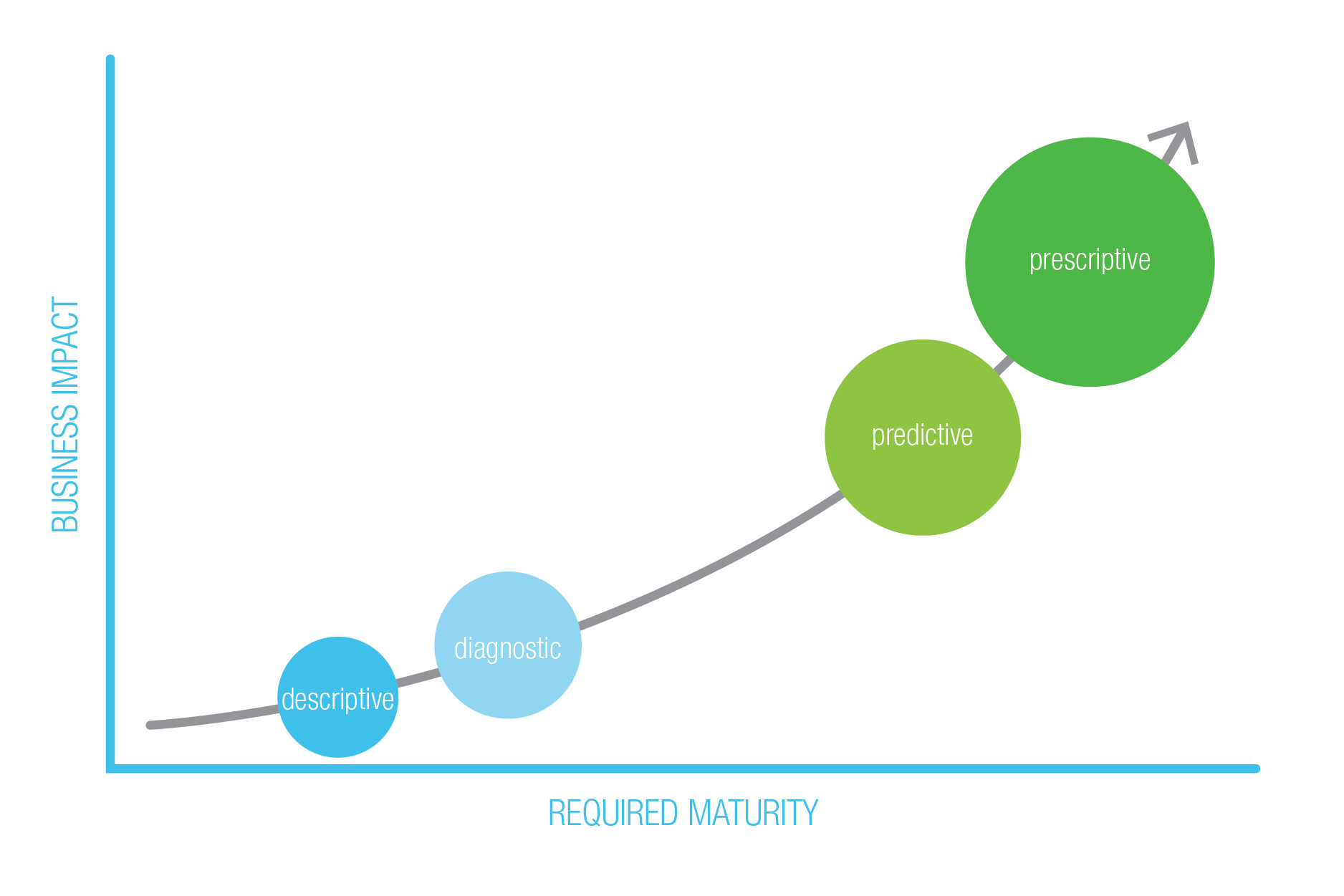 Descriptive
Descriptive
Streaming data is supporting the business critical move to advanced analytics and streaming data analytics. As we move up the evolution and maturity curve, we start with the capturing of streaming data, as discussed previously. Ingesting data with high velocity, and often high variety, allows for new descriptive analytics and speed to insights.
Diagnostic
Next up the curve, diagnostic analytics puts contextual awareness around streaming data, by enriching streaming data, which is often stateless. Other streaming and static data tied to the streaming data flows give the ability to paint a fuller picture. At this point in the curve, streaming data operations such as aggregating data, joining data, performing windowed averages, and more, lead to more real-time correlations and better decision making. For example, social media and point-of-sale interactions could be captured on the edge and produced to a streaming data platform, such as Kafka, which could join these streams and provide holistic insights into a customer experience.
Predictive
Next in the curve, predictive, is where we can begin applying machine learning models to the novel streaming data. To begin, in a batch oriented environment, a model could be trained on enriched streaming data that’s been landed in an appropriate data structure, as well as run on new enriched streaming data after it’s landed. Additionally, in near-real time, we could take that model that has been trained on existing data, and now run this model on data as a step in the stream processing pipeline, as an enrichment step before it’s landed.
Prescriptive
Lastly, in prescriptive analytics, apply an action in-stream to trigger actions and/or automated processes based on the marriage of results of streaming data analytics and business rules.
Data Flow: What’s Out There?
The landscape of streaming data tools and platforms is changing rapidly, but can broadly be broken down into four areas.
- Traditional enterprise event streaming platforms (Ex. Oracle SOA Suite)
- Open-source streaming projects and processing tools (Ex. Kafka, Spark Streaming)
- Subscription-based streaming platforms and processing tools (Ex. Confluent Kafka, Databricks)
- Cloud-based streaming services and processing tools (Ex. Amazon SQS, Amazon Lambda, Azure Stream Analytics)
What’s Next?
Stay tuned for a deeper dive into this breakdown, and examples of technologies and streaming data implementations. Overall, when deciding a streaming data tool or platform, we can focus on a few key questions. Where is your streaming data currently located? Where are your current skill sets with both data processing and captured data? Where are you looking to go with your streaming data footprint, and through the streaming data analytics maturity curve?
Related Posts



Comments (0)