
Keeping company data safe is a top priority in a fast-paced…
We’ve previously addressed how OAuth is a critical component of API Security for modern applications because it provides a means for end users (a.k.a. resource owners) to authorize application access to personal resources. Even though it’s primarily an authorization process, authentication does play a critical role, too, as we need to make sure that it is the legitimate resource owner providing consent and not some other person. By design, authentication occurs between the resource owner and authorization server and excludes client applications. This means that clients really only know whether authentication was successful or not (i.e. whether they receive a token an error message). Unfortunately, clients often need more information than that, such as attributes about the authenticated user and/or session. For example, what if the application wants to show a display name after authentication, or pre-fill form with a phone number for text notifications? Or, what if the client wants information about the session, like when it expires so it can silently extend the session to keep the user from spending time to re-authenticate later? These are the kinds of gaps that OpenID Connect was created to fill.
What is OpenID Connect?
OpenID Connect (OIDC) is an industry standardized authentication layer built over top of the OAuth framework to provide lightweight identity and authentication services. It provides a RESTful protocol for client applications to initiate authentications and retrieve data about authenticated resource owners and their sessions that they otherwise wouldn’t be able to get. Because it is based on OAuth, the roles and processes involved are very similar, but there are several key differences. Let’s look at a few of them.
ID Tokens
First of all, in OAuth client applications receive scoped access tokens that authorize use of a set of API resources. These tokens are opaque to the clients and on passed to the APIs. In OIDC, client applications obtain id tokens which contain claims, or assertions, about identity attributes of the end user or the authentication event. Instead of being opaque to clients like access tokens, id tokens are cryptographically signed Java Web Tokens (JWTs) that can be read, verified, and used by the client applications themselves. At a minimum, id tokens will contain the username of the authenticated user, the issuer of the token, and details about the token lifetime, but they can also contain additional claims, such as the name, contact information, or other demographic data of the user. Claims are requested as OAuth scopes, and there is a predefined standard set of them encompassing the most commonly used identity attributes. Custom claims can also be added to id tokens if your application needs something not available in the standard claim.
Authentication Flows
The basic OIDC interaction involves most of the same entities as in OAuth, though they are given different names. OIDC interactions involve the Relying Party (i.e. client application), the end user (i.e. resource owner), and the OpenID Provider (i.e. Authorization Server). In the diagram below, we’ve shown both OIDC and OAuth names for clarity. Notice that Resource Servers (i.e. APIs) are not present since id tokens are not usually passed to them.
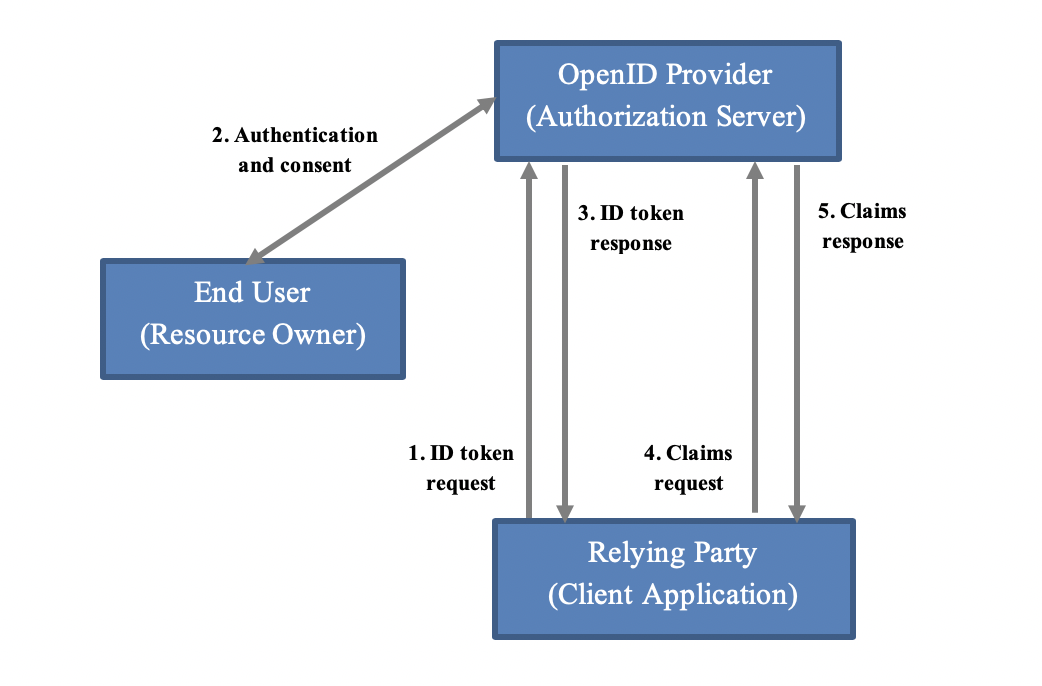
When a relying party or RP wants to authenticate the end user or obtain an id token, it (1) issues a request with a special openid scope and scopes for any other desired claims (e.g. email address phone). The OpenID Provider or OP (2) interacts with the end user to perform authentication if no valid session is already present and obtain consent to the requested scopes/claims. If the user consents, there are two ways claims can be returned, depending on how the client requests it. Either the OP (3) responds with just an id token or it responds with an id token and an access token. In the former case, all claims are embedded directly in the token for immediate use. In the latter case, claims are split between the two tokens, with some embedded in the id token for immediate use and others only available when the RP later (4) uses the access token to retrieve them. The OP (5) will return the claim values as long as the access token is valid. Normally, most claims will be retrieved via access tokens, but clients can request how claims be distributed between the two types of tokens. Lastly, refresh tokens can also be provided for clients to get offline access to identity claims without user interaction.
As with OAuth, there are different options for how client applications actually obtain id tokens and access tokens. These are the OIDC authentication flows and are built on top of OAuth authorization flows. Putting aside some specifics around endpoints and message exchanges, there are generally three supported OIDC authentication flows. As with OAuth, all of them are based on HTTP and occur over a secure connection, since we are dealing with user credentials. Authentication and consent is directly between end user and the OP so credentials aren’t exposed to client applications. Here is a brief overview.
- Implicit Flow – This is the simplest authentication flow. Relying parties simply request claims, and after the resource owner authenticates and consents as described above, receive the token(s) from the OP. This flow has actually been deprecated because of security concerns around token exposure, but it is still commonly supported for backwards compatibility. Also, clients in this flow don’t authenticate to the OP and refresh tokens aren’t supported.
- Authorization Code Flow – This flow operates in two phases. In the first phase, which is unauthenticated, client applications receive a short-lived authorization code from the OP after the resource owner authenticates and consents. In the second phase, clients exchange the authorization code for the token(s), authenticating to the OP if they are able. The two-part nature flow is more secure since it keeps tokens out of browsers for certain kinds of clients (i.e. server-side applications). Refresh tokens are supported.
- Hybrid Flow – This flow that can be seen as a sort of combination of the two above flows. It has the same two part structure as the Authorization Code flow, but more flexibility. It provides the option for clients to receive id/access tokens with the authorization code as well as after exchanging the authorization code. Depending on the provider, different sets of identity claims could be returned to the client before and the client authenticates. Refresh tokens are supported.
There is also a fourth, less common but very interesting, extension flow worth mentioning.
- Client-Initiated Backchannel Authentication Flow – In this flow, the client requests the OP initiate authentication with the end user via a separate authentication device, such as a mobile phone, and then either polls or is pushed tokens from the OP. This is intended more for step-up authentication or re-authentication scenarios when the client already knows the identity of the user. Refresh tokens are also supported in this flow.
In all of these authentication flows, client applications can also request specific authentication actions from the OP, such as extending the current session with no additional authentication, forcing re-authentication of the user, forcing re-consent of scopes, or even, if the provider supports it, requesting a particular method of authentication, e.g. SMS. These options give clients a high degree of influence over the timing, type, and strength of authentication performed by the OP.
How should you plan for an OIDC implementation?
Now you’re armed with this prerequisite understanding of key concepts; what are the next steps? If you’re implementing OIDC on top of an existing OAuth stack, the changes to your infrastructure will be relatively minimal, but if you’re starting from scratch with both, you will want to read our OAuth blog for a list of additional impacts. Here are some steps to facilitate your OpenID implementation.
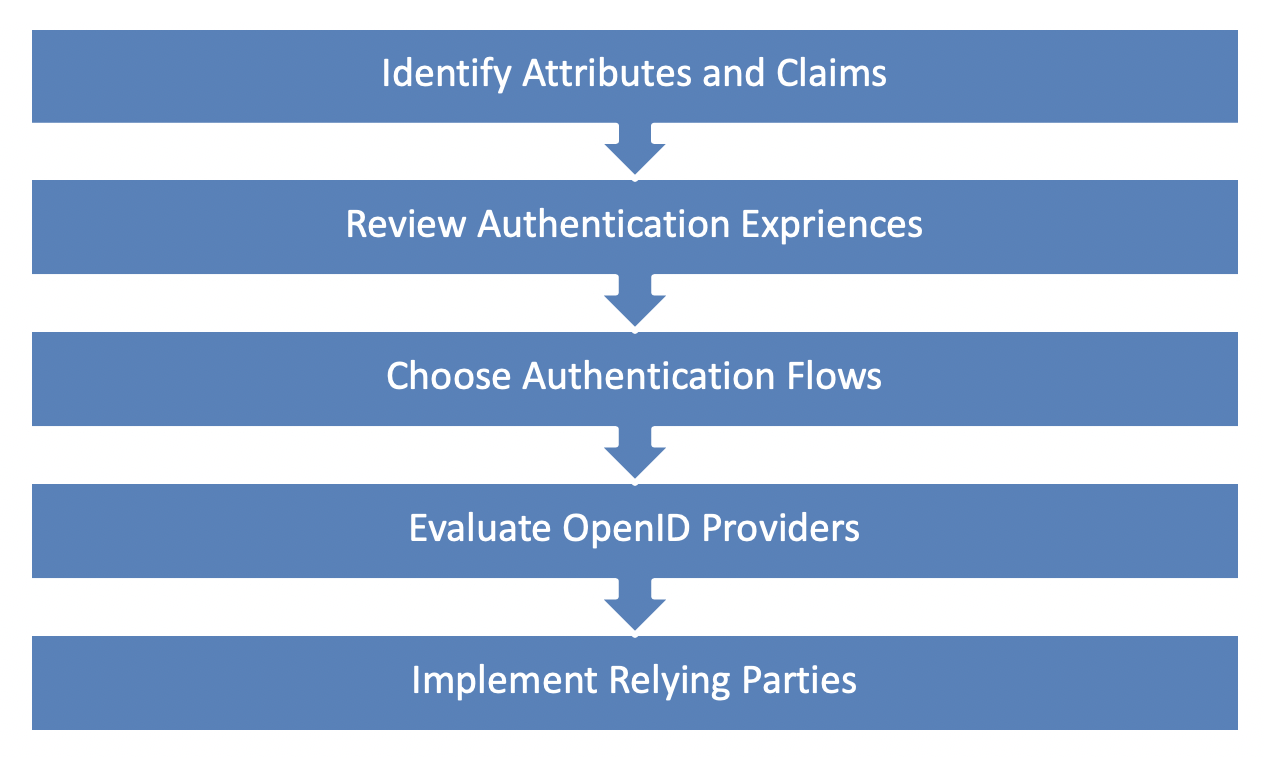
1. Identify Attributes and Claims
First, you’ll need to do an inventory of the identity and authentication attributes your applications consume. Consider each current client application and any application planned for future development and determine whether the attribute is part of the standard custom claim set or not. With this knowledge, you can work with your OpenID provider to ensure the necessary data is available as custom claims will require special configuration or customization.
2. Review Authentication Experiences
For each client application, consider what identity data is needed and when it is needed. Think of what level of authentication is required to obtain that identity data. Is the data needed immediately upon initial authentication, or only for some occasionally used application feature? Are there application actions that require repeat or step-up authentications, e.g. MFA for financial transactions? These authentication experiences help determine not only application authentication flows, but also the authentication capabilities of the OP. Furthermore, it may be the case that current UI flows for authentication/consent may need additional messaging or screens to handle authentication flows, e.g. a new screen to repeat a consent. If you want to use backchannel authentication, you will also need to determine your set of supported apps/devices.
3. Choose Authentication Flows
Because OIDC is built on OAuth, it also uses two categories of client applications: confidential clients, which are under a high degree of control and can be trusted to securely store secrets/tokens, and public clients, which are under less control and cannot be trusted to securely store secrets/tokens.
- Server-side web applications will be confidential clients that authenticate to the OP. They should use the Authorization Code or Hybrid flows, because they are more secure, keeping sensitive tokens and claims away from the browser. They can also use the Backchannel Authentication flow for step-up scenarios.
- Browser-based web applications are public clients. They will also use the Authorization Code or Hybrid flows, but there is a PKCE extension that should be incorporated for additional security. However, if the application is only using the bare minimum default claims, the Implicit flow could suffice. The Backchannel Authentication flow cannot be used because public clients do not authenticate.
- Native applications may be confidential or public depending on how highly managed the hosting device is, e.g. a locked down workstation with tight security controls versus a common, every day smart phone, but they are usually public. Thus, they would most often use the same flows as browser-based web applications with the same caveats.
Regardless of the authentication flow you choose, be sure not to request identity data or refresh tokens unnecessarily, especially not to public clients, and handle them securely to reduce unnecessary data exposure. This could potentially mean that your client application should be re-architected to move some functions server-side so that tokens and identity claims can be handled more safely.
4. Evaluate OpenID Providers
Now, claims, authentication flows, and user authentication experiences in mind, you can determine what capabilities your OpenID provider(s) will need. Which one(s) you choose depends on where user identities are currently managed and the attributes/experiences that need to be supported. Here are a few possibilities.
- Social Providers – If your application users are consumers at-large and you need to store no special information about them, you have the option of using public Social Identity providers, consisting of the likes of Google, Microsoft, and Yahoo among others. If you expect users to have accounts with these vendors, they can be quickly integrated with as they will be tried and true. However, you will have almost no control over the attributes available or the user experience.
- Federated Providers – If your users are partner identities from a federation you participate in and all identity data you need is stored there, you can use any OIDC services your partner offers. You’ll also be limited to the capabilities and user experiences of the partner, but you might have more ability to influence identity attributes or business processes than public providers.
- In-House Providers – On the other hand, if you already have “local accounts” maintained for application users on-premises or in the cloud or if you need more control over identity attributes and authenticate processes than a federation partner can provide, then setting up your own provider may the best option.
If you do need to set up your own OpenID provider, you should look at existing investments to see what OIDC capabilities they have, always paying attention to license models and operating costs.
- Access Management platforms, like Oracle Access Manager and Okta, are based on a user directories and naturally provide OIDC identity services on top of that directory layer. They will support the standard identity attributes and have a default set of UI experiences, but they will also have plugin points to customize how claims are handled and how authentication screens and flows play out. If you have highly specific or non-standard attributes to support, these platforms will be your best bet.
- Cloud platforms, such as Microsoft and AWS, that offer an IAM layer will also have OIDC provider services. They will not support the same degree of extension and customization that AM platforms will, however, and are more suited to common OIDC use cases.
- Open source and custom solutions can also be used if there is a strong need for a feature that isn’t supported by an existing cloud or AM vendor. A list of certified open source provider libraries is available. Of course, your liability is higher with these as you must develop the new features yourselves.
5. Implement Relying Parties
After choosing OIDC providers for an application, you need to register the corresponding application client, distribute the client credential if necessary, and authorize the claims/scopes they are permitted to request. Providers will offer capabilities to dynamically register a client via API calls, but you will also be able to create clients manually. Which method you choose really depends on how much oversight you need over client credentials and metadata.
From a coding perspective, OIDC is REST-based specification so all providers will have REST web services for client applications to call. If you prefer a higher-level programming language, there is also a set of certified client libraries. In either case, we strongly encourage adopting or implementing your own client library so that you can standardize best practices and control the timing, error handling, and security aspects of OIDC credential and token management and shield these details from application developers. Best practices for OAuth and OIDC are available here.
Conclusion
OpenID Connect was engineered on top of the OAuth framework to provide lightweight authentication and identity services, and is ideal for retrieving information about users and sessions from remote identity stores. Together with OAuth, it forms the IAM stack for modern application development and API Security, so whether you plan to create a new application from scratch or replace out outdated identity integration in an existing one, it is important to plan thoroughly. That said, it’s also important to execute the plan, so start small and choose your most critical apps and services and start with those.
Zirous is an experienced strategic partner who understands how company needs and processes affect governance strategies, access management, and API security. Reach out to learn how our partnerships like Oracle, SailPoint, and Okta can provide value to your organization.
Related Posts


This Post Has 0 Comments