
What is Cortex AI? Cortex AI is Snowflake’s native AI solution…
Apache Kafka has recently released version 2.5, which has brought its share of exciting new changes to the Kafka Streams DSL. A great time to look at our architectures, and determine how they can be improved using the new features available to us as developers. I often work with streams of relational data from a relational database management system (RDBMS), like Debezium. With relational data being based on foreign keys to other tables, it is important to know how to join this data within Kafka Streams. I would like to go over how I currently handle certain situations with joining this data and how my methods can be improved with these new features.
A Kafka Streams Stateful Recap
In Kafka, there are two kinds of operations, stateless and stateful. When a stateless operation is made on a Kafka message, it can be done totally independently from any other message processing. This makes the operations quick and light-weight. For more advanced stream processing (like joining streams) one can use stateful operations, which hold state locally in what is called a state store, and utilize that state to make decisions.
In Kafka Streams Processors, the two primary structures are KStreams, and KTables. KStreams are streams of messages on a Kafka topic, marked by offsets. A KTable is a key/value store that is kept up to date by aggregating an incoming KStream. From this wording we can tell that a KTable is inherently stateful as it operates on a “store.” With these two building blocks we can perform the majority of the stateful operations provided with the Kafka Streams DSL. The Kafka documentation has a really handy image that I have included below, going over the different operations available for each and how it transforms what you are operating on.
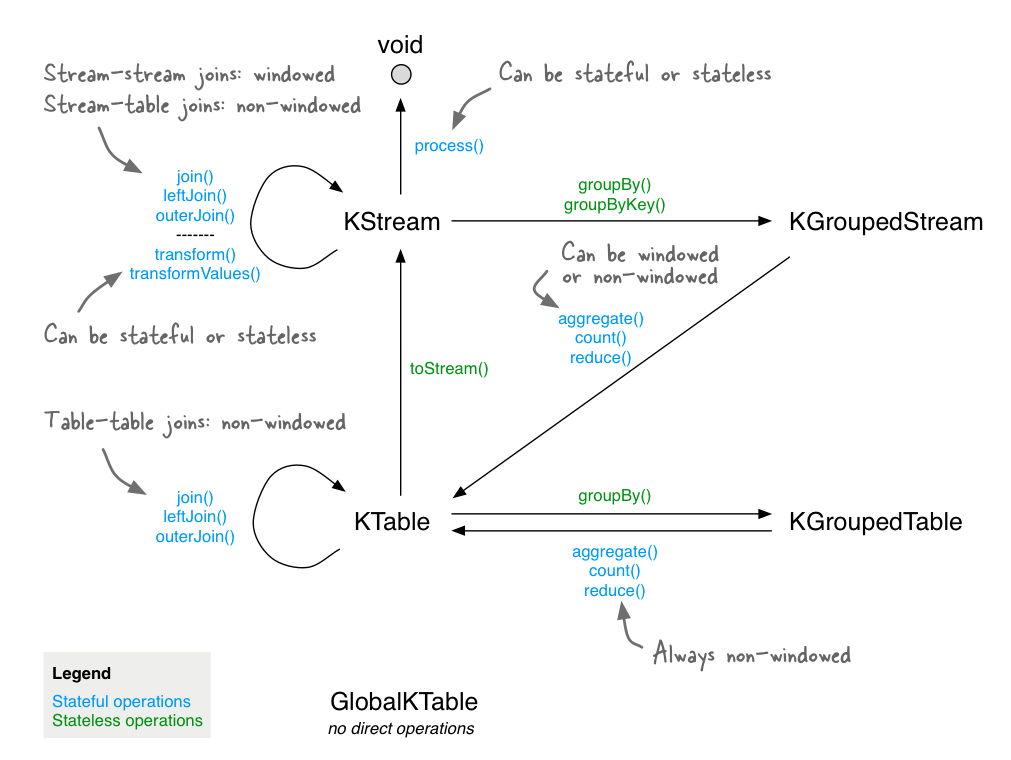
New Features
KTable Foreign Key Joins
Up until Kafka 2.4.0, it was required for KTable-KTable joins to be keyed the same, and if they weren’t, you would need to do a groupBy and an aggregation to fully re-key the table. This is a bit of a pain as every additional KTable in the flow adds another state store that is taking up space. If you need to do this join for more than two KTables, it only gets messier. That’s why I was so excited to see the foreign key lookups have become an option for KTable-KTable joins! Now, using a “foreignKeyExtractor” we can join a KTable to another based on a foreign key in its value. This is unbelievably handy and saves so many lines of code and pointless re-aggregations. You can read more about this method in the Kafka Streams DSL here.
CoGroup
Joins are very common in processing relational data, and when you need to join X number of KStreams together, it can be a tedious process. If you want to output one record for every input to X streams that joins to the others, then you will need to use an inner join on the streams aggregated as KTables, which requires all of the KTables to be keyed the same. To get each stream to that state, use selectKey to change the key, groupByKey to pull the common records together, then aggregate those GroupedKStreams into KTable format. Once that is done you have to iteratively join these KTables together, and handle merging each of their payloads.
Each one of those KTables we created in the last step would require their own state store, and depending on the retention policies you have set for Kafka and the amount of data you are streaming, this can become costly very quickly. As of Kafka 2.5.0, the cogroup functionality has been added. Rather than aggregating all of those KStreams into their own KTables, you simply get each stream grouped by its key, then cogroup all of those KGroupedStreams together. Now you still need to write out how these payloads will come together piece by piece, but by removing the need to go to KTables first, we have effectively removed half of the aggregations and all but one of the state stores in our example! The savings in both lines of code and storage space on your Kafka Streams processors are substantial. You can read more about the cogroup method in the Kafka Streams DSL here. For some code examples that illustrate just how great this change is, check out the Apache Improvement Proposal that got this feature added here.
Conclusion
In terms of stateful operations on Kafka Streams, I think these are the two that are the most striking in terms of new functionality. If you are thinking about starting a new Kafka Streams process, I highly encourage you to go with the latest version to take advantage of them. I hope my examples have given you some ideas as to how to make a sleek and efficient flow in your new and existing projects.
Related Posts



Comments (0)