
What is Cortex AI? Cortex AI is Snowflake’s native AI solution…
With all of the exciting new tools to analyze and look at data, it’s easy to get swept up and forget about a very important part of the process. Getting data to those tools! That is where tools like NiFi and Kafka really shine. They allow developers to quickly set up data pipelines that can span entire enterprises! But what are the differences between them? Which one should you use? In this blog I will discuss the different features of these tools, and where I see them being used best.
NiFi
NiFi is a data flow tool that was meant to fill the role of batch scripts, at the ever increasing scale of big data. Rather than maintain and watch scripts as environments change, NiFi was made to allow end users to maintain flows, easily add new targets and sources of data, and do all of these tasks with full data provenance and replay capability the whole time.
NiFi encompasses the idea of flowfiles and processors. A flowfile is a single piece of information and is comprised of two parts, a header and content (very similar to an HTTP Request). The header contains many attributes that describe things like the data type of the content, the timestamp of creation, and a totally unique ‘uuid.’ Custom attributes can also be set and operated on in the logic of the flow. The content of a flowfile is simply the raw data that is being passed along. It could be plaintext, JSON, binary, or any other kind of bytes.
Now to operate on these flowfiles and make decisions, NiFi has over one hundred processors. A processor is a standalone piece of code that performs an operation on flowfiles, and does so very well. By having every processor follow the same ideology of reading and writing flowfiles, it is very easy to assemble a totally custom dataflow with just the processors that come with NiFi, not to mention any custom ones you may write yourself.

NiFi sets itself apart from other dataflow tools with its web interface, which provides the ability to have authenticated users drag and drop processors and create connections on a live view of the flow. This allows the staff monitoring NiFi to quickly react and reroute data around issues that come up during processing. The community surrounding NiFi has also created tools to maintain schemas and versions of a NiFi flow, so that it may be version controlled.
From my experience, NiFi’s best role in a data pipeline involves connecting many disparate systems, handling non-critical independent data (like IoT device logs), and having a visual for how data is flowing throughout the application.
Kafka
At its core, Kafka is a distributed fault-tolerant publish subscribe system. While that sounds complex enough, that is really just scratching the surface of what all of Kafka’s additional tools are capable of. To break down Kafka, it is a cluster of servers called ‘brokers’ tasked with ingesting data from sources called ‘producers’ and outputting it to ‘consumers.’ When a producer sends a message to the Kafka cluster, they specify a ‘topic.’ A topic is a collection of messages that are replicated and organized by offset, which is an incrementing value assigned to every message added to a topic. This offset allows for replayability in reading the data, and for consumers to be able to pick and choose their pace for grabbing messages from the topic. Kafka is distributed so that it can scale to handle any number of producers and consumers.
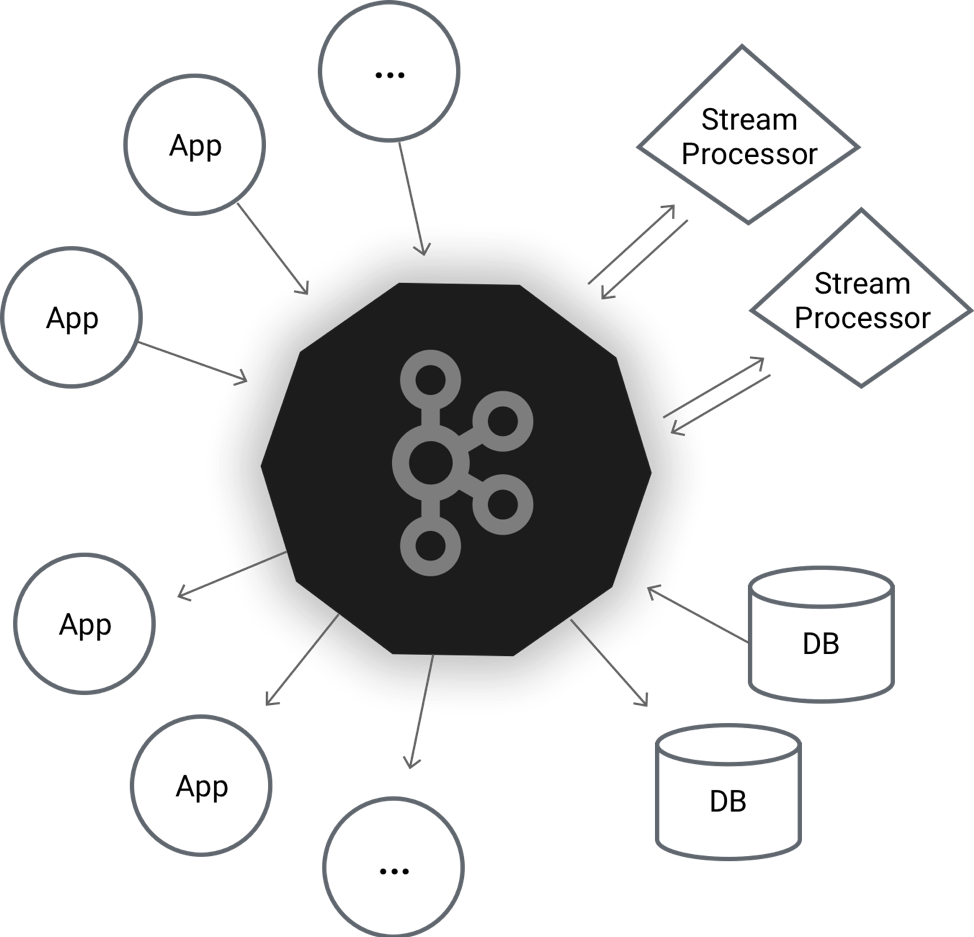
So you put things in one end of Kafka, and they come out the other, where does my ETL and routing happen? In comes Kafka Streams. Kafka Streams is a lightweight client library intended to allow for operating on Kafka’s streaming data. It work by declaring ‘processors’ in Java that read from topics, perform operations, then output to different topics. This allows total customizability as Java is very flexible and allows you to route, alter, and filter messages midstream.
Now Kafka is a very powerful dataflow tool; however, I would note that it does require experience working with command line applications, and does not have an official UI (although Landoop is certainly worth mentioning!). I believe Kafka excels when you know you will need to reprocess data, data is critical and needs to be fault tolerant, and when the dataflow will be supported by a technical team.
The Verdict
You may have guessed it from the title, but I think the best solutions will use a combination of both tools where they fit best! NiFi has processors that can both consume and produce Kafka messages, which allows you to connect the tools quite flexibly. NiFi is not fault-tolerant in that if its node goes down, all of the data on it will be lost unless that exact node can be brought back. By outputting data to Kafka occasionally, you can have peace of mind that your data is safely stored and replayable in the flow.
To continue on with some of the benefits of each tool, NiFi can execute shell commands, Python, and several other languages on streaming data, while Kafka Streams allows for Java (although custom NiFi processors are also written in Java, this has more overhead in development). By using both, you have the greatest flexibility for all parties involved in developing and maintaining your dataflow. An example of this I encountered was when I had data sitting in a Kafka topic that I wanted to operate some of the Python sentiment analysis libraries on. I was able to consume the messages in NiFi, operate the Python on them individually, and produce the records out to a new Kafka topic.
I hope I’ve given you a fair taste of both tools and that you are now excited to incorporate them into you dataflows! You are in luck as both are open-source Apache projects, and don’t require a license to use, but they do require some expertise. Our data engineers at Zirous are familiar with both tools and would love to hear your questions on how they might integrate with your dataflow!
Related Posts



Comments (0)