
Last week Zirous attended Technology Association of Iowa’s 2026 Iowa Technology…
Using Clustering for Customer Segmentation
Clustering is a useful unsupervised method of machine learning, especially for identifying customer segments. Before, it was necessary to manually examine the qualities of your customers and make assumptions to discover what types of customers you had. But now, with machine learning – specifically clustering – your customer segments can be driven by their data and actions rather than assumptions. There are various ways to cluster your customers, but we will cover the use of an algorithm called K-Means.
Unsupervised Learning
Clustering algorithms fall into the category of machine learning known as unsupervised learning. This just means that there is no predefined “correct” answer, as there is in supervised learning. For example, if you’re trying to determine if a picture is of a cat or not, you will have a collection of pictures labeled ‘cat’ or ‘not cat,’ whereas with unsupervised learning, you can take a collection of images and group them into similar images, but the composition of the groups, or clusters, won’t be predetermined. In general, unsupervised learning is used to gain undetermined insight into your data, and supervised learning is used to automate processes based on your data.
Data Prep
Any type of machine learning still requires data preparation. Feature engineering, as with most machine learning solutions, is a major part of building clusters. First, the data on each customer is likely to be represented in various ways, such as purchase history and demographics. The purchase history for a customer is likely to be time series data, which will need to be aggregated into a more usable format. Demographic data is more likely to be made up of single data points such as age, marriage status, gender, and education level, so it will require less aggregation per customer.
For this demo we will use the “Online Retail Data Set” from https://archive.ics.uci.edu/ml/datasets/online+retail which initially looks like this:

We are interested in grouping customers, though, not invoices, so we will have to do some aggregation, to get statistics about each customer. Some of the things we’re interested in, for clustering purchase behavior, will be the total amount spent, the least recent order, most recent order, average amount spent, number of unique items bought, country, etc. After aggregation, our data looks like this:
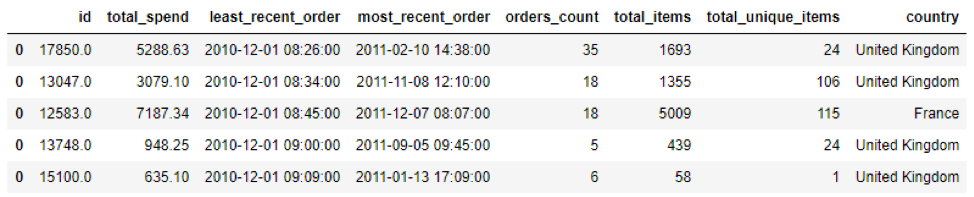
So now, for each customer (id) we have each of those features. Next we can engineer more features, such as average spent on each order, average spent on each item, average time between orders, etc. Also, because date isn’t especially helpful given its format, we will transform date to “days since…” to create a numeric feature. Because the dataset is from 2010, we will treat the most recent order from the dataset as the date the data was pulled, and compare all of our dates to that date. After engineering features about dates, we will add these columns to the dataset:
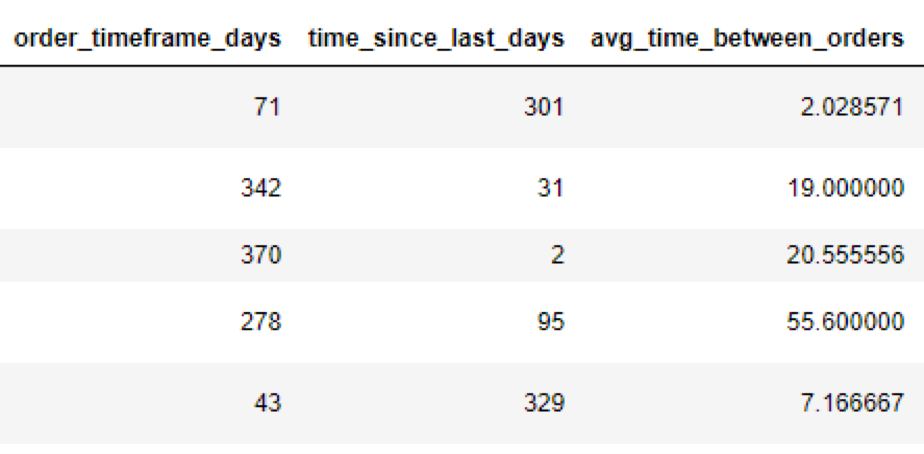
There are many more features that can be engineered, but for the sake of time, we will limit our feature engineering. The main point here is that you will need to aggregate and combine data about your customers.
Clustering
In order to cluster effectively, your data will most likely need to be scaled. This is because different numeric features have different ranges, so features with wider ranges will have a bigger impact on the clustering algorithm. For example, if you cluster on the total spent compared to the number of orders, the former will be in the thousands, but the latter will be in the dozens. The algorithm will treat total spend as being more influential to cluster creation simply because it has a wider range. In this example we will use min-max scaling, which transforms the data, so that for each column the maximum value is 1 and the minimum value is 0, so that all features are on the same scale. It is necessary to scale ordinal (ranked) values as well, but categorical variables will most likely not need to be scaled. Now, the data will look like this:

We will join the scaled data to the original data though, so we can get a better idea of clusters once they’re made.
K-Means
The algorithm we will use is called K-Means. This unsupervised clustering algorithm takes the data and the number of clusters (K) you want to create as inputs and assigns the data to one of the K clusters. You might be asking, “How do I know how many clusters to create?” We will use a metric called within-cluster sum of squared error (WSSE) and make a scree plot to determine a good number of clusters. (Note: K-Means is susceptible to being influenced by outliers, so we have removed customers with extreme values for each column.)
To make the scree plot, run the clustering algorithm with K ranging from 2 to 40 and store the WSSE for each K, then graph WSSE values. A minimum of 2 clusters is required, and a maximum needs to be a number that makes sense both mathematically (based on the scree plot) and operationally. In other words, how many clusters can you actually manage and use effectively? A maximum of 40 clusters for our scree plot will give us a wide range to view. We will also use the scaled data when creating these clusters.
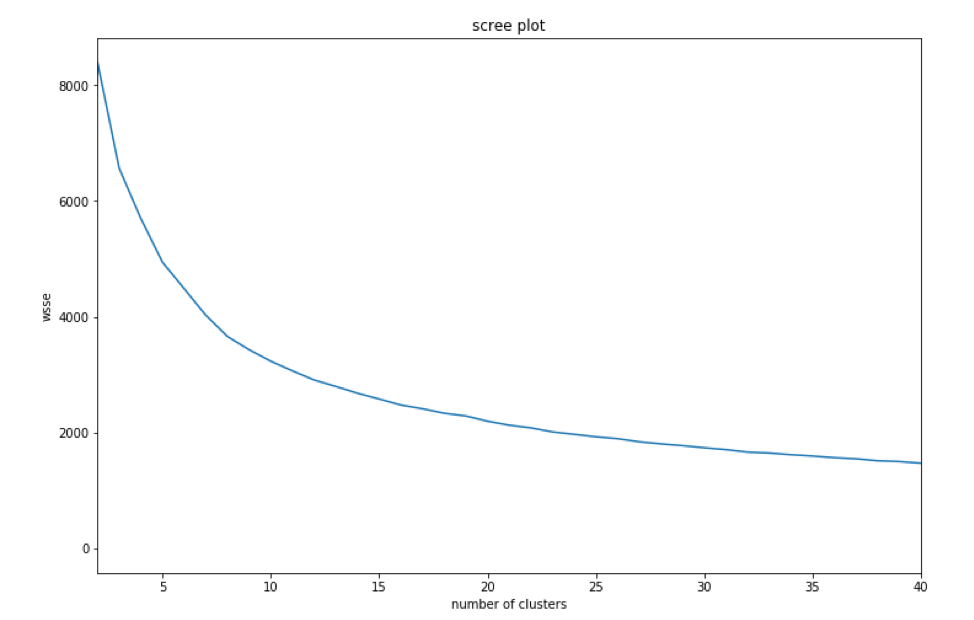
After creating the scree plot, look for where the “elbow” of the plot is; this is the optimal number of different clusters. Here, the elbow is the 8-15 cluster range, so we will evaluate some of those clusters more closely.
Cluster Analysis
Three Clusters
To warm up, we will look at the results of K=3.
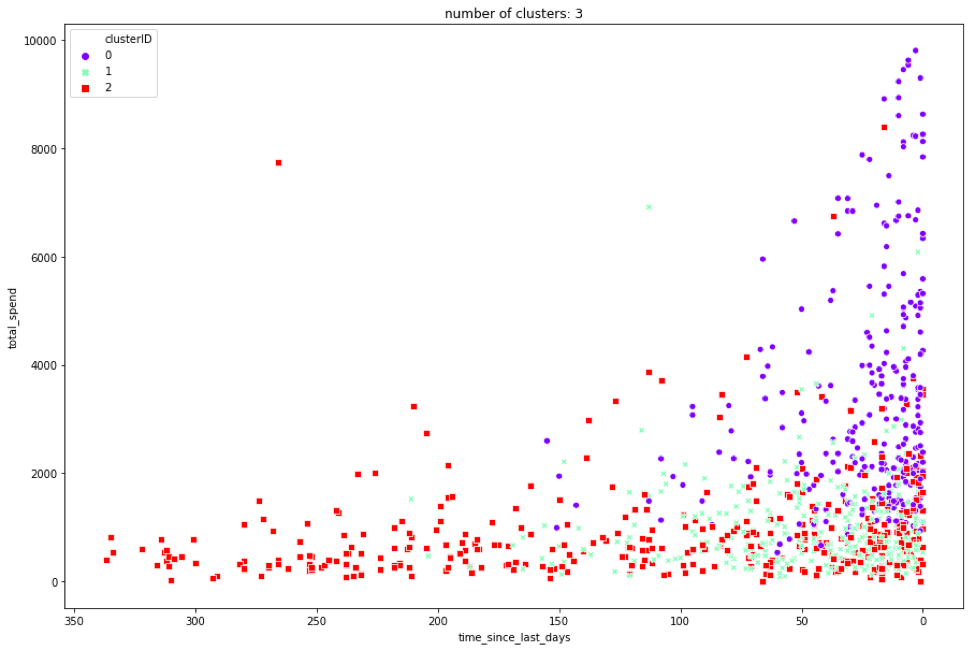

This case is fairly obvious. We can see on the graph that, in general, cluster 0 has a higher total spend and purchased recently, cluster 1 has purchased recently but hasn’t spent much, and cluster 2 hasn’t purchased recently and has a low total spend. By looking more closely at the table, we can see that cluster 0 has a much higher order count, number of unique items bought, and a lower time between orders.
Eight Clusters
If we look at 8 clusters, they will be more descriptive, but also require a little more work to differentiate them.
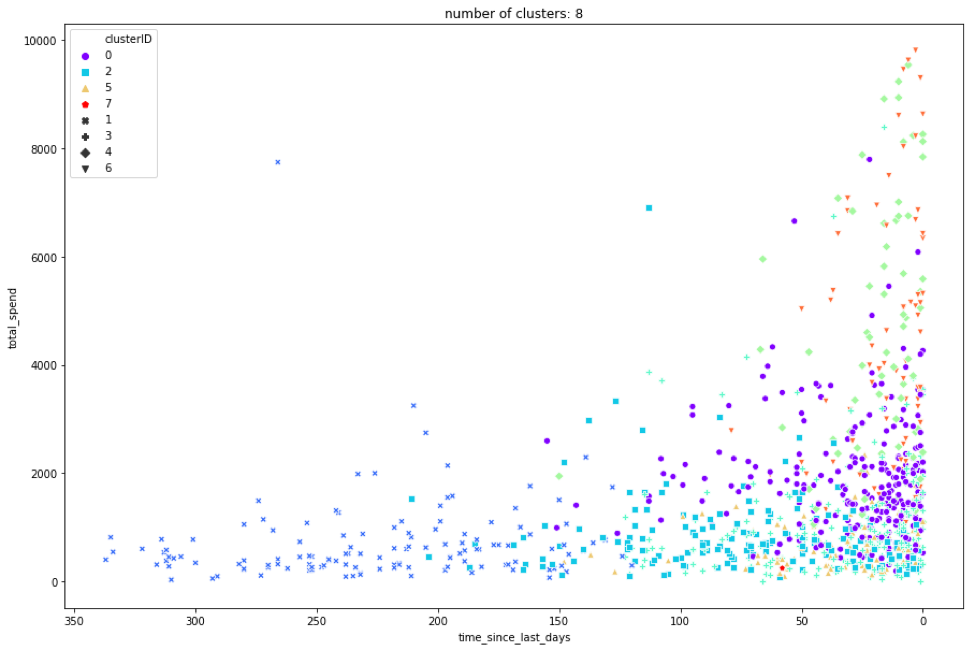
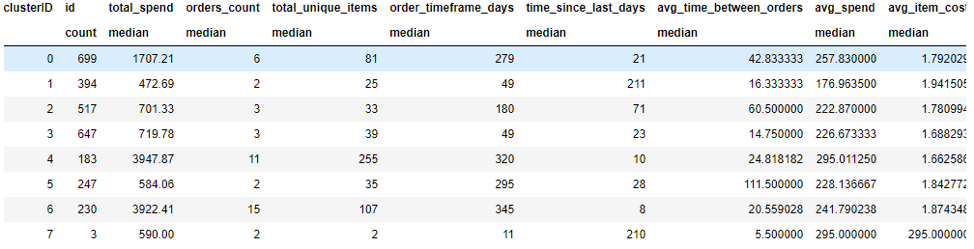
We can now see that the clusters overlap a lot more, especially in the lower right part of the graph, so we will need to look at the table for more information. We can still see that cluster 1 (blue X) hasn’t made a purchase in a while, and that seems to be the main factor for that cluster. However, we now have 2 clusters in the top right (cluster 6, the orange triangle; and cluster 4, the green diamond). If we compare them using the table, we can see that all of the columns are similar, except that cluster 4 has over twice as many unique items purchased.
We can also look at cluster 3 (green plus) and cluster 2 (blue square), which appear to have a lot of overlap. By looking at the table, though, we can see they’re similar in every column except the timeframe in which their orders took place. We can see that cluster 2 made its last order over two months ago, and bought every 60 days on average, but cluster 3 buys more frequently and is more likely to turn into a high-value customer, if they don’t churn.
As you can see, the more clusters we use, the more differentiators appear between them. You can find even more interesting similarities and differences between clusters here by examining the graph and table further.
—
Though we’ve taken a behind-the-scenes look into machine learning here, it’s also important to note just how much a solid machine learning strategy can impact your business strategy and bottom line. This one example of clustering, paired with your own knowledge of your business, can be used to determine:
- Which customers might churn, and how you can prevent them from doing so
- Segments of customers that might purchase more with a simple nudge
- Customer groups your marketing team can use to more effectively place ads and launch campaigns
- Types of customers that are missing from your business and whether or not there is potential for new segments of customers
No matter your industry, customer insights are critical to your business. Utilizing machine learning to uncover greater insights about your customer base can lead to increased revenues, decreased costs, increased efficiency, and much more.
Zirous’ data engineering and machine learning experts (not to mention our joint venture Zirobi) can help you prepare your data for machine learning, perform the analyses needed to uncover unknown insights and answer specific questions, and operationalize the results into your daily activities seamlessly within any business department.
Related Posts



Comments (0)