
Last week Zirous attended Technology Association of Iowa’s 2026 Iowa Technology…
Machine Learning and Flip Phones
Doing data analytics in Excel is like tweeting from your flip phone. It’s time to move on.
It was January 2007. I had just started my last semester of high school when Apple made an announcement that would change the world. Prior to the iPhone’s release, you needed two devices to listen to music and call your friends on the move. I had friends in high school who said, “Why would I need a phone that plays music? I have an MP3 player and a cell phone.” I have no doubt that today, these people have embraced the convenience of having MP3 players, GPS’s, PDA’s, and cell phones all in one device, and can see how the first iPhone revolutionized the way we live.
My friends who didn’t see the point of the iPhone are like companies today who are hesitant to utilize machine learning for their customer-centric analytics. They think, “We’ve been running this successful company off of spreadsheets and pivot tables for years. Why would we need to change something that isn’t broken?” Companies who are pushing back on utilizing machine learning are going to miss their chance to gain a competitive edge in today’s marketplace. Some companies will continue to be like my friends who didn’t see the value of the iPhone, but others have already started benefiting. Machine learning is the iPhone of the business world.
Machine Learning Capabilities
Most companies want to have the best understanding of their customers as possible, whether it’s to figure out which types of customers are the most valuable (and keep them), to anticipate customers who are about to churn, or to predict how much a customer is likely to spend on gifts this holiday season. The possibilities are endless if you truly understand your customer. You may have heard of Customer 360: a complete view of your customers. While there are myriads of data available about your customers, it’s almost impossible to gain insightful information without machine learning.
There are a few types of machine learning modeling, each with different approaches to answering customer-related questions. Clustering algorithms define what groups of customers you think you have, or help you discover new ones. Classification can predict which customers won’t come back. Regression can predict how much the customers who come back will spend. Traditionally, companies have used spreadsheets and statistics to do their analysis, but those can be limited. The only limit to machine learning is the power of your computer(s).
“Okay, so tell me more about machine learning,” you say. Well, machine learning is a key role in why data science is such a booming field. In some cases it’s PhD level work, discovering formulas and publishing academic papers. But in many cases, it’s just analysis on steroids.
Next Level Analytics
Everyone knows your basic stats functions: mean, median, mode, regression, and maybe something like method of moments or confidence intervals from college stats, but machine learning is what really takes analytics to the next level.
Excel is limited to 20 variables and around a million rows of data for linear regression, but Python or Spark can handle anything (if you have the compute power). DriverlessAI from H2O will examine up to 10,000,000,000 rows of data, if you want it to take the time. In general, ML can handle billions of rows of data and thousands of features, but it’s not necessary to have that much data to get a useful result by using machine learning.
Okay cool, so machine learning can look at more of your data than traditional analytics, but what’s the point? In general, ML can make predictions from your data or can find insights that would be impossible for a human to find because of the number of variables. You can think of each variable or feature of your data as a dimension. It’s easy to look at your data in 2 or 3 dimensions. But how do you look at your data when there are hundreds of dimensions? This is where machine learning comes into play.
Machine Learning Algorithms
So, how do machine learning algorithms work? First, we should cover two major categories of machine learning: Supervised learning and unsupervised learning.
Supervised Learning
Supervised learning is used when you have data that is labeled, i.e., you know the outcome that should happen or actually happened on some historic data. This data can be used for training regression algorithms, which will predict “how many” of something will happen, or classification algorithms, which will predict what “type” a new data point would be.
One of the most intuitive classification algorithms is called k-nearest neighbors (or k-NN), where k represents the number of neighbors to look at. In this case, let’s say k is 5. So, when a new data point is classified, the algorithm will look at the 5 points closest to the point it’s trying to classify, and chose the one class with the most points nearby. Algorithms like this are useful for predicting if a customer is likely to churn, or if a person (or group) is likely to buy a specific product.
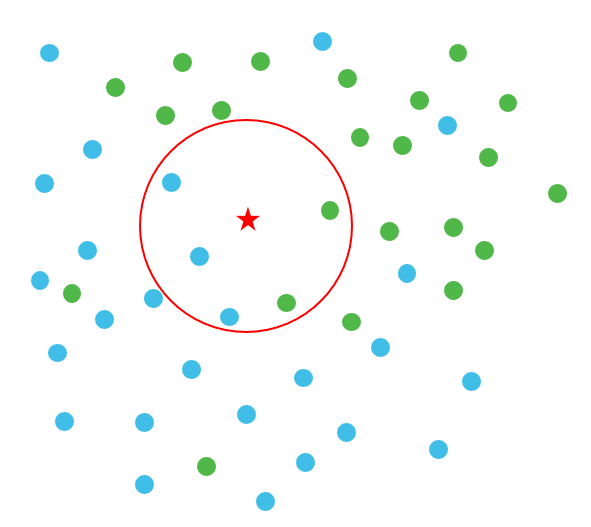 k-NN with k=5. The star would be classified as a blue point.
k-NN with k=5. The star would be classified as a blue point.
Regression algorithms are similar to classification algorithms in that you have historic labeled data for both. In regression, though, you have a value instead of a label. This could be the number of customers in a store, the amount of web traffic you get, or power usage. Regression algorithms start to blur the lines between statistics and machine learning, as they are generally just applied statistics algorithms. However, statistics has traditionally been used to summarize what happened in the past. Machine learning takes it to the next level: predicting what will happen in the future.
Unsupervised Learning
Unsupervised learning is another major category of machine learning. It is useful when you don’t have specific labels on your historic data, but you want to discover insight. It is literally unsupervised exploration of your data. For example, if you want to know what intrinsic groups your customers fall into, a clustering algorithm would help you. To find the most defining features of your dataset or reduce their complexity, a dimensionality reduction algorithm would be best.
One particular clustering algorithm, hierarchical clustering, works by treating every individual point as its own cluster, then finds the two closest clusters, then merges them. The algorithm iterates until all of the clusters have merged together. Once the algorithm is complete, you can decide on how many clusters you want to use, and work backwards from the completion of the algorithm to identify the clusters. A dendrogram (shown below) visualizes the hierarchy of clusters for us.
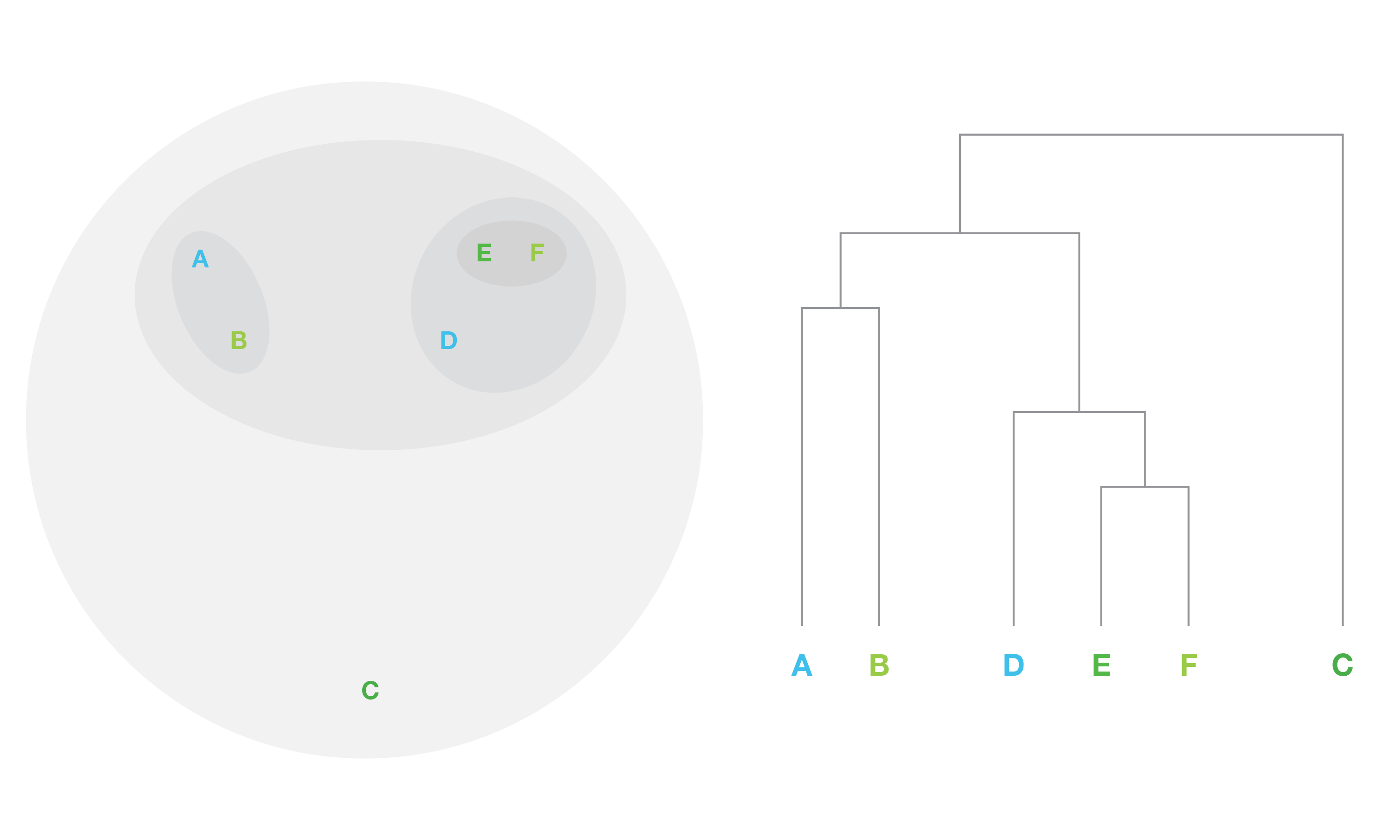 Hierarchical Clusters and Accompanying Dendrogram
Hierarchical Clusters and Accompanying Dendrogram
Clustering can be a key part of customer 360. Once you have as much data as possible on your customers, how do you use it? Clustering can look at your data and objectively identify differentiators between groups of customers so you can properly segment and target these customers more accurately and individually.
Dimensionality reduction is another unsupervised technique. It’s unique, however, because rather than directly providing predictions, it transforms your data so other algorithms can predict more easily. When the algorithm reduces the number of dimensions of your data, it also identifies the most important dimensions. This reduced complexity makes it easier to run other algorithms. Dimensionality reduction works by identifying new axes with the most variance and readjusting the data to fit these new axes. It’s easiest to see if you have two dimensions. Even in only three dimensions it becomes difficult to visualize.
Below you can see that all of the points fall on a line, but it takes an x and y coordinate to describe their location. If we shift the axes by rotating the graph, we can see that these points can be represented in a single dimension, without losing any variance in the data. We can now see that this data is completely explained by 1 component. This algorithm is call principal component analysis (PCA) based on the principal components of each new axis.
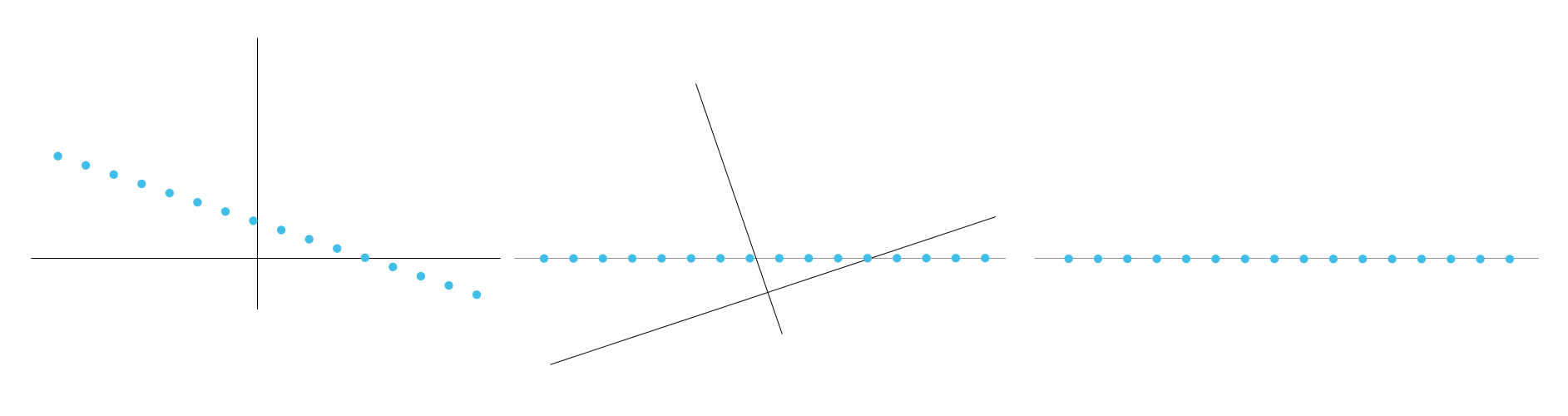 Principal Component Analysis
Principal Component Analysis
—–
The iPhone was revolutionary – and some thought unnecessary – upon its release in 2007. But of course, we’ve all seen how that turned out. There’s no denying that the same thing will happen with machine learning. But instead of your friends poking fun at you for being a laggard in the iPhone space, your company could go out of business if it’s a laggard in the analytics space. With so many practical applications available within machine learning, there’s something for everyone and every business.
The Zirous machine learning team and I have worked with companies of many sizes and industries to take their analytics practices to the next level, solving not just data problems, but business problems. Get in touch with us if you have questions about how machine learning can help your business.

Tyler Bybee
Machine Learning Engineer
Related Posts



Comments (0)