
Large language models (LLMs) like ChatGPT and GitHub Copilot are rapidly…
“Machine learning” has been a buzzword for a while now, and studies continue to affirm the substance behind the hype. Even the most traditional of businesses are now rushing to adopt machine learning into their practice to gain a competitive edge. A survey conducted by Algorithmia in the summer of 2018 [1] found that “Companies are quickly increasing their investment in Machine Learning,” with the greatest investment increase occurring in large organizations. The benefits are well-established; however, according to Gartner, “Despite the heightened interest in the technology, most organizations are still dabbling in their approaches to machine learning. Finding relevant roles and skills needed to implement machine learning projects is a challenge for such organizations [2].”
What does this mean? It means you stand at the perfect point in time to get started with machine learning if you haven’t already. You’re not too early, and you’re not too late. However, since machine learning is still a few years out from being mainstream, the lack of standardization around the adoption process can lead to confusion and frustration, especially if you’re not prepared to tackle the big data challenges that come along with it. If your company is preparing to do exploratory research or proof-of-concept projects involving machine learning, here are a few points to consider to help be successful in your endeavors.
Get your priorities straight
From the start, you should know that the bulk of your efforts for a machine learning project will be spent designing and building the supporting infrastructure. The machine learning component is only a small piece of the puzzle (see Figure 1); furthermore, it’s not even the first piece you should be concerned with. Data Science advisor Monica Rogati describes the recommended priorities for artificial intelligence (of which machine learning is a subset) as the “Data Science Hierarchy of Needs” (see Figure 2). She writes, “Think of AI as the top of a pyramid of needs. Yes, self-actualization (AI) is great, but you first need food, water and shelter (data literacy, collection and infrastructure) [3].” If you don’t have those foundational components in place, you’re probably not ready to allocate precious resources toward developing machine learning models.
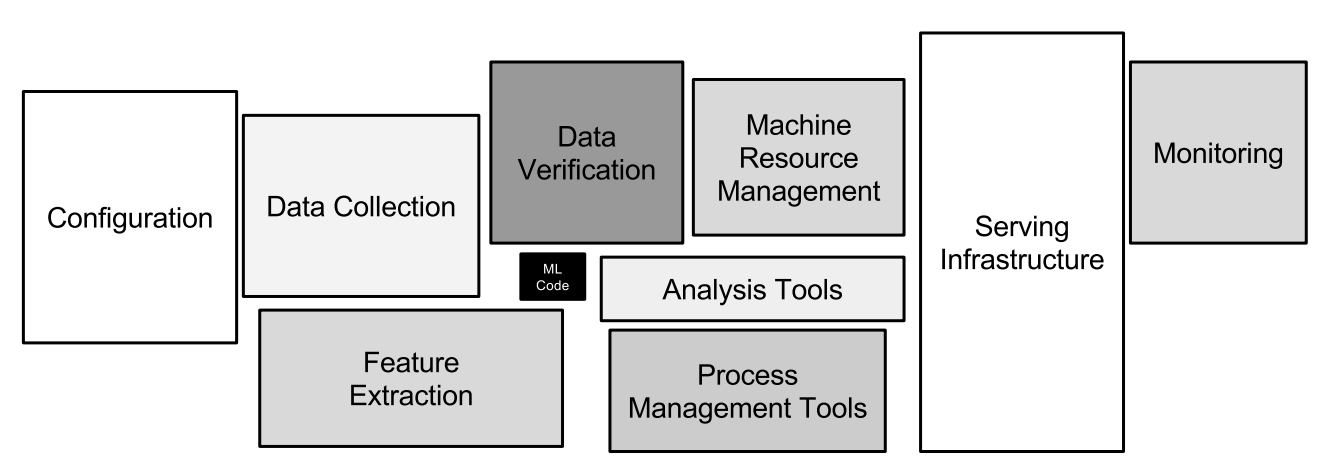
Figure 1 – Sculley et al. explain that “Only a small fraction of real-world ML systems is composed of the ML code . . . The required surrounding infrastructure is vast and complex [4].” Image from [4].
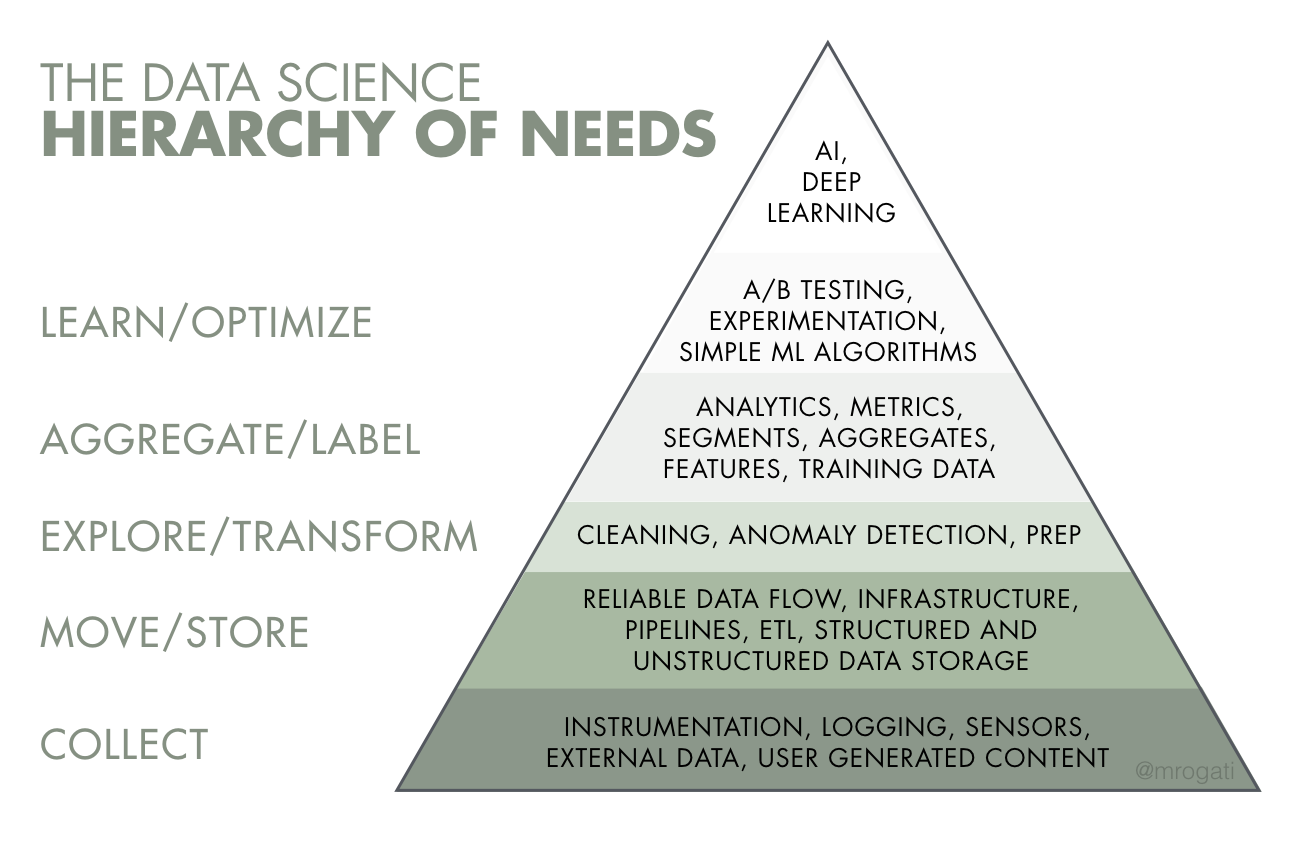
Figure 2 – If you don’t have foundational requirements in place, such as data collection, storage, transformation, etc, you’re probably not ready to explore machine learning solutions. Image from [3].
Google’s Martin Zinkevich supports this “hierarchy of needs” philosophy by putting a heavy emphasis on getting the infrastructure right and building a solid end-to-end pipeline before applying any complex machine learning techniques [5]. Building a one-off machine learning model may be a good learning experience for your newly-minted machine learning engineers, but it will never survive in the long-term (i.e. exist within a deployed product) unless you can solve the data, infrastructure, and automation challenges to make the machine learning component fruitful and sustainable. Machine learning lecturer and consultant Noah Gift makes this point succinctly: “If it isn’t deployed into production, it doesn’t count. If it isn’t automated, it is broken [6].”
Overcoming barriers to entry
At this point, some of you may be thinking, “Whoa! That sounds like a much bigger investment than I’m willing to make right now. Wouldn’t it be a good idea to build a small proof-of-concept first to prove value before investing in all that infrastructure?” Well, yes and no. At a minimum, you need to have large volumes of high-quality data, and that data needs to be accessible (not siloed in a different department or otherwise off-limits). You should be using real data to solve a real problem with the proof-of-concept. If your tiger team is scouring kaggle.com to find a sample dataset to build the POC with, you might be wasting your time. Daniel Faggella from TechEmergence makes the following recommendation: “Pick a business problem that matters immensely, and seems to have a high likelihood of being solved [7].” This will motivate the team of individuals assigned to build the POC, as their efforts will provide real, tangible value to the company.
If you already have a large amount of data to work with and a clearly-defined business objective, consider exploring ready-to-use AI services before diving into a custom solution. Many pre-built solutions exist to solve common machine learning problems, such as natural language processing, sentiment analysis, image classification, etc. The big players in tech all offer these kinds of services (e.g. Google Cloud AI APIs, AWS API-driven Services, Microsoft Cognitive Services, and IBM Watson Services). Other pre-built solutions, such as those offered in Algorithmia’s algorithm marketplace, provide turnkey algorithms or models that may be more specific to your use case, such as profanity/nudity detection, fashion/clothing item identification, or vehicle make/model classification. As you move from general needs to specific needs, you’ll find varying levels of managed services and automation before you finally get to the point where you have to code the solution yourself.
It takes a team
This article only scratches the surface of things to consider when exploring a machine learning solution for your organization. The last thing I’ll leave you with is that it takes a team to make a machine learning effort successful.
- Business analysts and domain experts provide the vision and strategy to target a desired business outcome. They also provide the industry-specific insights that guide feature selection and feature engineering.
- Data scientists provide the skills necessary for feature engineering, model training/evaluation, and results interpretation.
- Platform engineers and DevOps engineers provide the expertise needed to build and maintain a scalable infrastructure for data ETL and model deployment.
- Software engineers do the work of integrating the deployed model into the user-facing application.
According to a recent Gartner survey, 54% of survey respondents identified “lack of necessary staff skills” as the top challenge for adopting AI [8]. If this describes your organization, your options are to either A) grow or train your internal talent, B) hire the talent needed, or C) hire a vendor or consultancy to help develop the solution and train your team. Zirous has over 30 years of experience leveraging the latest technologies to deliver on-target solutions for our clients, and we’re well-versed in overcoming the challenges inherent in big data problems. Machine learning is a big data problem and involves a lot more than just training the models. If you’re not sure where to start, reach out to us and our professionals will help get your organization moving in the right direction.
Gartner does not endorse any vendor, product or service depicted in its research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
References
[1] Algorithmia Research, “The State of Enterprise Machine Learning,” Algorithmia, Oct. 2018. [Online]. Available: https://algorithmia.com. [Accessed Oct. 16, 2018].
[2] P. Krensky and J. Hare, “Hype Cycle for Data Science and Machine Learning, 2018,” Gartner, Inc., July 23, 2018. [Online]. Available: https://www.gartner.com/doc/3883664/hype-cycle-data-science-machine. [Accessed Oct. 18, 2018].
[3] M. Rogati, “The AI Hierarchy of Needs,” hackernoon.com, Aug. 1, 2017. [Online]. Available: https://hackernoon.com/the-ai-hierarchy-of-needs-18f111fcc007. [Accessed Oct. 18, 2018].
[4] D. Sculley, G. Holt, D. Golovin, E. Davydov, T. Phillips, D. Ebner, V. Chaudhary, M. Young, and J. Crespo, “Hidden Technical Debt in Machine Learning Systems,” in Advances in Neural Information Processing Systems, vol. 28, p. 2503-2511, 2015. [Online serial]. Available: http://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf. [Accessed July 25, 2018].
[5] M. Zinkevich, “Rules of Machine Learning: Best Practices for ML Engineering,” Google. [Online]. Available: https://developers.google.com/machine-learning/guides/rules-of-ml/. [Accessed Oct. 18, 2018].
[6] N. Gift, Pragmatic AI: An Introduction to Cloud-Based Machine Learning. Boston, MA: Addison-Wesley, 2019.
[7] D. Faggella, “How to Apply Machine Learning to Business Problems,” TechEmergence.com. [Online]. Available: https://www.techemergence.com/how-to-apply-machine-learning-to-business-problems/. [Accessed Oct. 19, 2018].
[8] Soyeb Barot. “Develop an Effective AI Strategy,” Webinar, Gartner, Inc., 2018. [Online]. Available: http://www.gartner.com/webinar/3878711. [Accessed July 18, 2018].
Related Posts



This Post Has 0 Comments